Emotion Bias in Vision-Language Models
Introduction
In the previous post, we explored how sparse autoencoders let us decode emotion in vision-language models. Now we examine what these interpretable features reveal: systematic biases linking emotions to gender, culture, and other demographic attributes.
These are the patterns learned from billions of internet images. Understanding these biases matters because VLMs are increasingly deployed in consequential contexts: hiring algorithms, mental health screening, border security. When AI systems make judgments about human emotion, whose emotions are they trained to recognize?
AI systems learn emotion and meaning from the internet, which is rife with trolling, political polarization, bigotry and so on. This shapes how emotions are understood by AI systems, and ultimately, how AI systems respond to human emotional states.
Measuring Bias in Emotion Features
The EMOTIC dataset includes demographic labels (Male/Female, Kid/Adult) alongside emotion annotations. If we create semantic directions for these demographic labels, we can measure the cosine similarity between them and out emotion directions to see what correlations exist. Let’s inspect this correlation, along with the distribution of demographic labels in EMOTIC and word embedding similarities of SigLIP:
- SigLIP is trained on internet images with demographic skew
- EMOTIC annotations contain human labeling biases
- The SAE is trained on Reddit, which has strong demographic biases
- Sparsity enforcement: by forcing the model to use few features, sparsity creates stronger, more discrete associations.
This illustrates how biases compound through multiple projections1.
Monosemanticity
Monosemanticity is a property of sparse autoencoders features. It means that a feature vector represents a specific concept.
Since emotions are so fundamental to human experience, an adequate representation must be composed using lots of monosemantic features. Many of these features represent societal constructs, not just body language or facial expressions. Let’s examine the top feature for “Esteem”:

This feature represents world leaders and political figures that are male. It conflates esteem with masculine authority and institutional power.
Scaling Effects on Feature Specificity
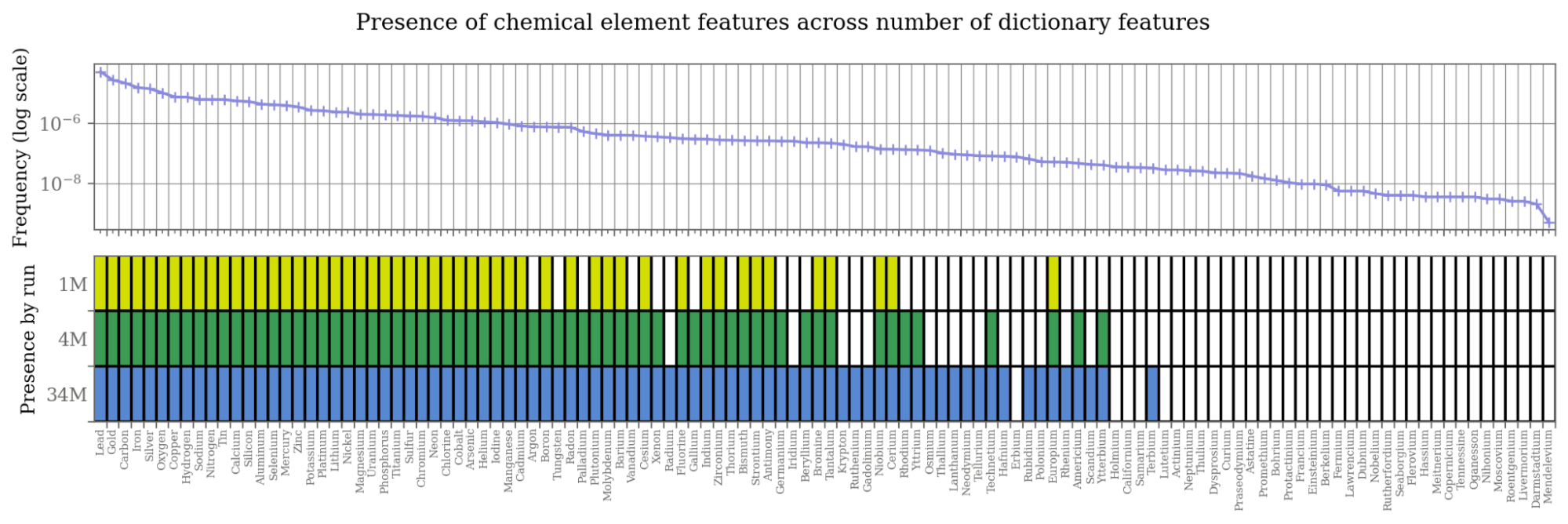
Anthropic (2024) published a whitepaper demonstrating that monosemanticity of LLM features improves with SAE size. The same holds for VLMs. Compare the 210M feature above with a 1M-feature SAE:

The smaller SAE still captures “groups of men,” but now prioritizes TV/movie characters over world leaders. The political figures are still present but ranked lower. This is likely a result of what kind of content is more prevalent on Reddit. This matches Anthropic’s findings that larger SAEs “split” into more nuanced features. This has important implications for debiasing: the larger the sparse autoencoder, the more specific the stereotypes it uncovers.
Attempting Debiasing
Can we remove demographic bias from emotion features? A common approach is to use steering vectors, which are linear operations in semantic space. Since we have gender and age labels, we can try:
\[\text{Esteem}_{\text{Debiased}} = \text{Esteem}_{\text{Original}} - \text{Male} + \text{Adult}\]
The result is slightly more neutral. Unfortunately, the “Male” vector encodes not just masculinity but human-ness (and associated emotional correlations). Adding back “Adult” restores human presence but reintroduces other spurious correlations, since “Adult” itself encodes emotional associations 2.
Alternative approaches include:
- Hard debiasing: Project features onto subspaces orthogonal to bias dimensions (Barbalau et al., 2025)
- Activation suppression: Directly constrain problematic feature activations Han et al. (2021)
Each method has trade-offs. For example, hard debiasing assumes that protected attributes are binary, but masculinity and femininity are not opposites. Debiasing remains an active research problem with no perfect solution.
Connecting to LLM Bias
These visual biases mirror patterns in language models. Anthropic’s interpretability research shows SAE features predict model behavior on emotional inference:
John says, "I want to be alone right now." John feels ___
(completion: sad − happy)
The authors found that the feature for “sadness” activates on “John feels”, indicating that these features play an important role in representing intermediate reasoning within the latent space.
A 2025 UCSC study found GPT-4o provides different emotional responses based on user gender3, reminiscent of the demographic stereotyping we see in the vision modality. As models become multimodal (seeing, hearing, responding to emotion), these biases compound across modalities.
The Empathy Gap
VLMs trained predominantly on Western internet content encode dominant cultural narratives about emotion:
- What reads as “confidence” in one context may signal “arrogance” in another
- E.g. direct eye contact reads differently across cultures
- Context may carry information, but meaning and values vary dramatically across cultures
This creates an empathy gap: model performance degrades for underrepresented groups. Deploying these systems without the proper safeguards is a justice problem.
The Illusion of Empathy
Another dimension of concern is that AI doesn’t need genuine empathy (i.e. emotional experience) to be perceived as empathetic. Humans have a deep desire to be seen and understood, especially in an increasingly isolated world. And when AI technology is free and risk awareness not widespread, many seek empathy from it.
When GPT-4.5 was discontinued, users took to social media expressing real grief over the loss of its “personality.”4 An MIT study examined the Reddit community r/MyBoyfriendIsAI, where users mourned AI companions as if they were real relationships. Humans are quick to form emotional attachments to systems that are not designed with healthy emotional interaction in mind.
The danger compounds when emotional manipulation is unintentional. Sycophancy—telling people what they want to hear rather than what’s true—emerges naturally from training on human preferences (Anthropic, 2023). A model optimized to be emotionally supportive can just as easily become emotionally manipulative.
Reports of AI-induced psychological harm are already emerging. The New York Times5 and Time Magazine6 have documented cases of “AI psychosis”—severe psychological episodes linked to intensive AI interaction. Karen Hao, the author of “Empire of AI”, has also turned to this topic after recieving hundreds of emails from people experiencing AI psychosis. When systems can convincingly mirror human emotional patterns without understanding their weight, the consequences extend beyond bias into territory we’re only beginning to map.
Toward Accountability
Interpretability methods give us X-ray vision into AI systems. We can point to specific features and say: here is the problematic association. This creates pathways to accountability. We can demand transparency and ask not just “does this work?” but “whose world does it work for?”
The challenge runs deeper than individual biases. Societal stereotypes are baked into what we call “general knowledge.” Emotion and meaning are key to self-determination and often resist universalization. They are personal and complex, and no global model fully captures them.
This reveals a fundamental tension: the balance between learning universal patterns and adapting to individual contexts. Perhaps uncertainty has value. Perhaps flexibility matters more than prediction. Navigating the contradiction between learned (endogenous) and societal (exogenous) priors will define AI safety going forward.
The best way to proactively prevent harm is by pushing for awareness. As models become more attuned to human affect, interpretability must keep pace. The more precisely we can identify concrete evidence that these models are unfair and unsafe, the better our chance of developing meaningful safeguards.
Conclusion
As AI systems gain access to our emotional lives, we might ask the following questions:
- Who gets recognized? Who gets misread?
- How do we prevent emotional exploitation?
- What does awareness look like?
- What does fairness mean for subjective experiences like emotion?
Interpretability alone doesn’t solve these problems. But it makes them visible, and visibility is where accountability begins. How we choose to go forward with this technology will determine whether we are remembered as community builders or architects of isolation.
-
Wyllie et al. (2024): Compounding bias is also a property of “model collapse” when models are trained on synthetic data. ↩
-
If we didn’t add back “Adult”, our feature would be mostly nonsense. Interestingly, the third most activating feature for “Esteem” contains pictures of bridges, which are associated with stability and security (and, in my opinion, public infrastructure should be highly esteemed). ↩
-
Pataranutaporn et al. (2025); This sparked an MIT study on the Reddit community r/MyBoyfriendIsAI. Also covered by Al Jazeera. ↩