Interpretable Emotional Intelligence
Introduction
Empathy is one of the instruments that AI will need to wield in order to interact with society at a human-level. As it stands, AI is already capable of it—or at least it has us sufficiently convinced:
- In a UCSD study assessing the Turing Test for GPT-4.5, 73% of users could not tell the difference between a human and a chatbot. 1
- Many users took to social media in defense of GPT-4.5 when it was discontinued, claiming to have an emotional attachment to the personality. 2
- The New York Times, Time Magazine, Sycophancy3 and AI-induced psychosis4 have been linked to multiple deaths.
Technology has captured emotion and meaning as it exists on the internet, along with its biases and distortions. This manifests itself in subtle ways—a 2025 UCSC study found that GPT-4o provides differential emotional responses based on user’s gender. 5
Empathetic AI
Vision-language models (VLMs) relate text to images and can convincingly trace the outlines of human emotion through our systems of meaning.
This capacity for semantic understanding includes the association of certain emotions with visuals. However, this association is not always clear cut, and can be confounded by gender, culture, and other factors. Using sparse autoencoders, we can extract the latent features of images and inspect them for ourselves.
If you were to ask me what I think the most pleasing image is, I’d probably pick something that speaks to me personally—like a photo of my cat Ollie.
Affective Bias
Dominant narratives.
Superposition and Sparse Autoencoders
In 2023, researchers at Anthropic demonstrated that dense neural networks, “superposition”.
Sparse autoencoders are a type of neural network that learn to compress data down to its essential features. They consist of a encoder and decoder (two linear layers) and some form of regularization to enforce sparsity. They can be trained simply by comparing the MSE loss of the reconstructed output to the input:
Sparse autoencoders are used extensively for vision and language interpretability.
I trained a SAE on Reddit images, and extracted 65,000 features, corresponding to the dimensionality of the SAE. We can visually inspect a feature by sorting our images by how strongly they activate that feature. Some are inscrutable and odd, but a lot of them are interpretable.
Feature Filtering
One trick to sift through the SAE features and find the ones we care about is to collect a bunch of similar images as our “query” and see which features are most strongly activated. We can make it better by creating a “negative query” to subtract off noisy features.
To find the most pleasing image I used the EMOTIC dataset with 23k images of people labeled with 26 different emotions. One might think this limits our emotional intelligence to images of people, but by negative querying other emotions, and taking advantage of the SigLIP transfer learning, we filter out the shared features and generalize to other portrayals of emotion.

I was surprised to find that the resulting features are not limited to faces, and in some cases contain no people at all. Here is a website where I collected the top 20 example of the top SAE features activated by each emotion here (cw unfiltered reddit images).
Heatmaps
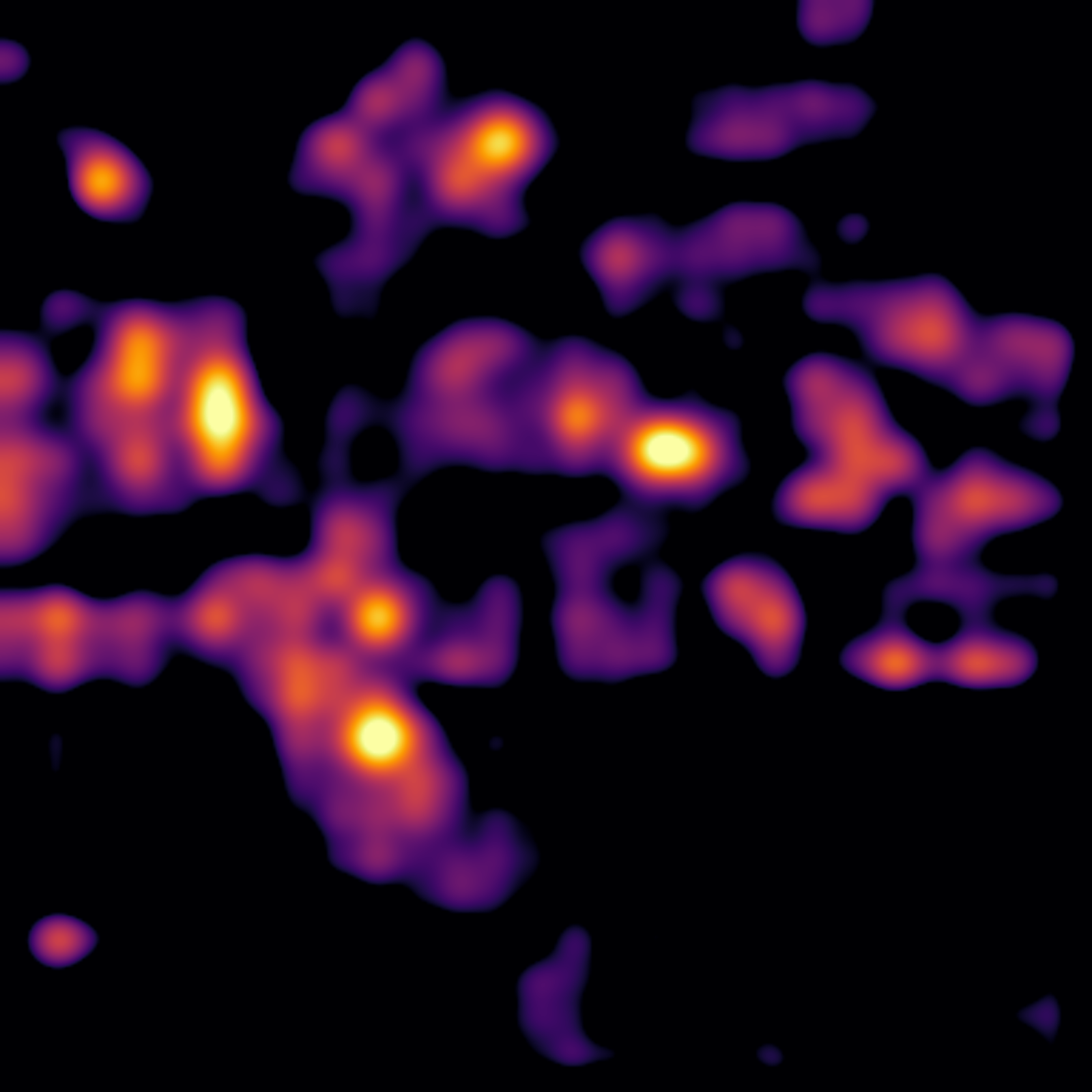
We can also use SigLIP to isolate what components of an image trigger a feature by creating a heatmap. Heatmaps aid in interpreting the model’s behavior and also serve as a kind of segmentation.
To create a heatmap for a given feature, we compute the gradient of the feature with respect to the input image. This is a common technique in computer vision called “saliency mapping”.
The saliency map is computed as follows:
- \[\begin{align*} &\text{Given: } x \in \mathbb{R}^{C \times H \times W},\quad \sigma > 0,\quad n \in \mathbb{N} \\ & G \leftarrow 0 \\ &\textbf{for } i = 1, \dots, n \textbf{ do} \\ &\quad \epsilon_i \sim \mathcal{N}(0, I) \\ &\quad \tilde{x}_i \leftarrow x + \sigma\epsilon_i\mathrm{std}(x) \\ &\quad g_i \leftarrow \frac{1}{C} \sum_{c=1}^{C} \bigl| \nabla_{\tilde{x}_i^{(c)}} f(\tilde{x}_i) \bigr| \\ &\quad G \leftarrow G + g_i \\ &\textbf{end for} \\ &S \leftarrow \frac{1}{n} G \end{align*}\]
-
G = torch.zeros_like(base[0]) # [H, W] for _ in range(n): noise = torch.randn_like(base) * sigma * base.std() x_noised = x + noise x_noised.requires_grad_(True) y = forward(x_noised) # simpler than score.backward() g, = torch.autograd.grad(y, x_noised, create_graph=False) G += g.abs().mean(dim=1) sal = G / n
This implementation also smooths the gradient by averaging over multiple noisy samples 67. Here is a comparison with and without smoothing:
| Raw Gradient | Smoothed Gradient |
|---|---|
 |  |
 |  |
Evaluation
We can use a linear combination of feature activations to predict the intensity of an emotion.
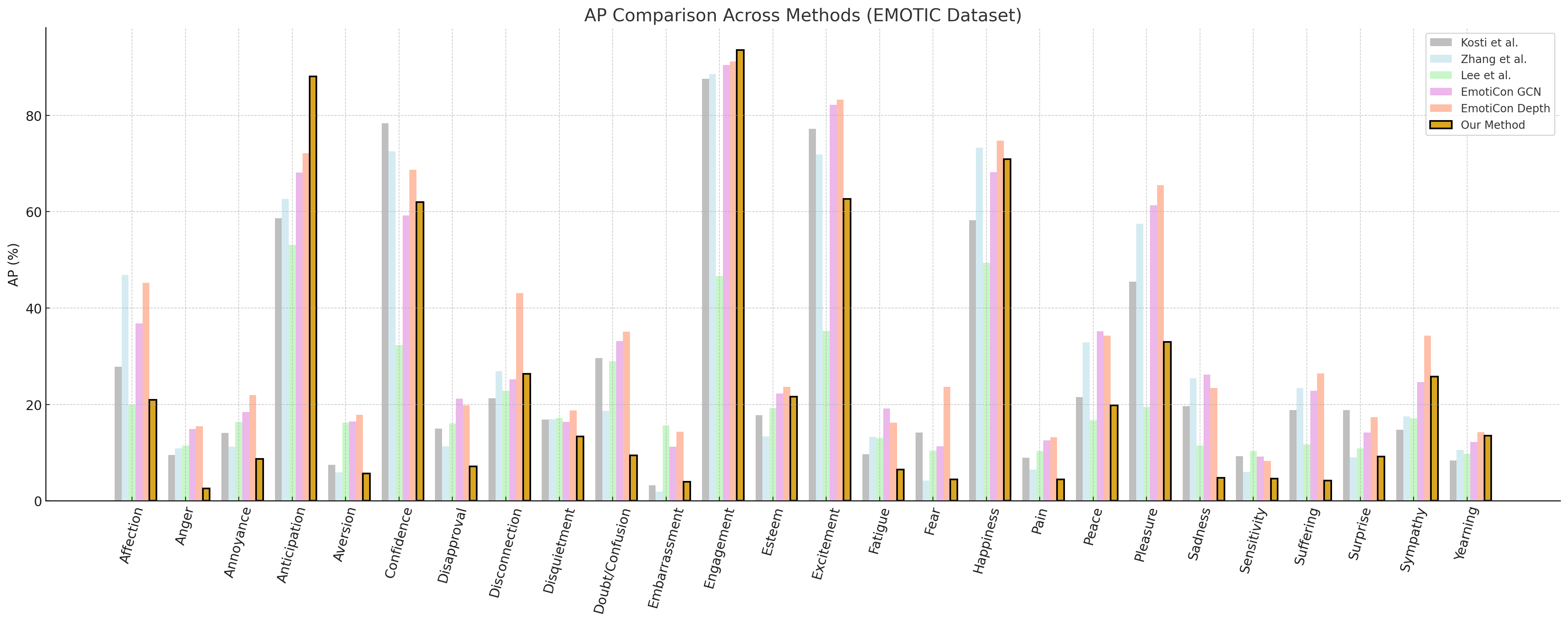
Filtering Bias
Sparse Autoencoders for Emotion (SAEFE) is a method to adapt vision-language models for emotion recognition using interpretable features.
SAEFE can be used to attenuate bias by adding or removing features that are associated with gender, age, race, or other protected characteristics.
SAEFE is released with a configuration tool to assist in feature exploration. The configuration tool provides an image search interface which retrieves Reddit images that have the greatest cosine similarity to the selected features.
Usage
First, a clip server with precomputed embeddings must be installed and running, such as this one.
The same SigLIP model must be used for compatibility with the trained sparse autoencoder.
Then, ENDPOINT in app.py must be set to the URL of the clip server. Run the app:
streamlit run app.py
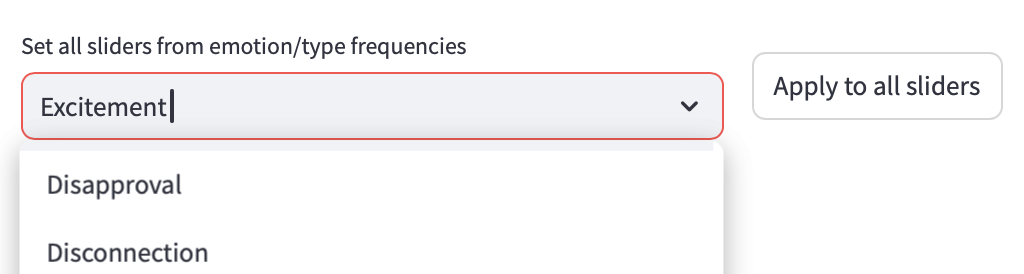
Use Case 1: Emotion Detection
The first use case is to search by label. Upon selecting e.g. “Excitement” and pressing “Apply to all sliders”, each feature is set to the average activation associated with “Excitement”. We can then search for images that are most similar to the label.
Use Case 2: Individual Feature Selection
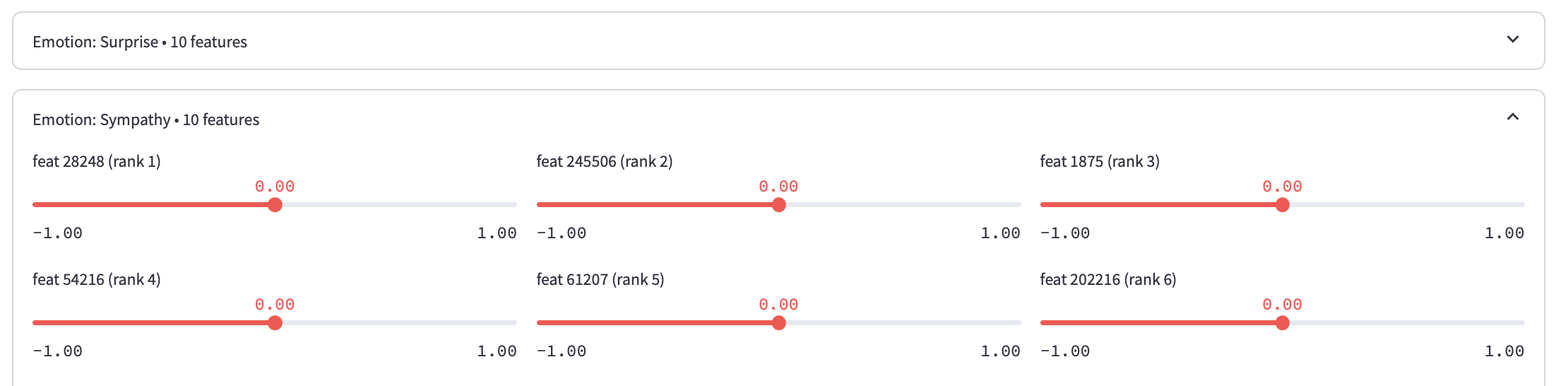
The second use-case is to search by individual feature. The top 10 features associated with each label is displayed and can be manually adjusted.
A negative value will maximize dissimilarity from the feature, a value of 0 is neutral to it, and a positive value will maximize similarity to the feature.
Use Case 3: Bias Attenuation
Certain features may align with biases in the dataset. For example, feature 61207, which is most associated with “Esteem”, encodes groups of men from TV shows and movies.
We can eliminate this bias in the Add/Subtract Label menu. There are pre-trained labels for gender and age. Using this menu, we can perform the following operation in semantic space:
\[Esteem_{Debiased}= Esteem_{Original} - Male + Adult\]Before Operation

After Operation

Discussion
Using SAEs, we can capture emotions as a linear combination of interpretable latent features. This is very useful for a few reasons. First, it allows us to read out multiple emotions with varying intensity. Second, we can directly inspect and tune out features that encode gender, race, or other biases 8.
There are clear gender biases in the results, which could stem from SigLIP, EMOTIC, Reddit, or all three. These sources are known to have distinct Western and gendered biases. Our analysis is limited since I only selected the top 5 features, which are not necessarily the most salient or representative. My hypothesis is that the gender-agnostic features are also activated strongly by the same emotion, but the feature is less prominent.
-
Esteem: The first feature shows men in positions of power, such as CEOs and politicians. The second shows Warhammer, PC builds, and guitars, which are associated with masculinity. The third consists of groups of men: IASIP, Modern Family, Brooklyn 99, Silicon Valley.
-
Disapproval: The top 3 features of disapproval consist of women.
My takeaway is that the highest ranking features might not be ideal for a properly aligned model because they encode some kind of bias. By tweaking the prominence of these features, we can potentially encode a model with better alignment.
Implications
This effort was inspired by the existing work “Contextual Emotion Recognition using Large Vision Language Models” on emotion detection using computer vision. The authors similarly used the EMOTIC dataset, but relied on a purely supervised approach and made note of the bias in the EMOTIC dataset. I was curious if a semi-supervised approach could be used to seek out relevant SAE features, potentially leading to a more generalizable model, perhaps with better control over the alignment.
Credits
Thanks to osmarks for the precomputed embeddings and SAE implementation.
-
Ma et al. via Stanford Law; The authors point out the limitations of the Turing Test as a measure of competency in real-world tasks, but I believe it is still relevant for mirroring human behavior and simulating empathy. Gary Marcus says the Turing Test is a measure of “human gullability”. ↩
-
Pataranutaporn et al. (2025); This sparked an MIT study on the Reddit community r/MyBoyfriendIsAI. Also covered by Al Jazeera. ↩
-
Anthropic (2023) published a whitepaper on sycophancy, showing that it is a general side effect of reinforcement learning with human feedback (RLHF). ↩
-
Psychology Today, The New York Times, and Time Magazine have covered AI psychosis. ↩
-
Roshanaei et al. (2025) via https://news.ucsc.edu/2025/03/ai-empathy/. ↩
-
Smilkov et al. (2017); SmoothGrad is effective, but it is expensive to compute the gradient multiple times. ↩
-
It turns out that attention itself is noisy. This substack post explains how ViT models sometimes stick global information in background patches, which can be resolved by adding CLS token “registers” during training. ↩
-
Wu et al. (2025) demonstrate how it is possible to remove gender bias from SAEs. ↩